語言是由文字組合出來的。作為一個人類,我們能夠將一篇文章分割成好幾個部分來閱讀和理解,為了讓電腦理解一篇文章,它也必須能夠這麼做。
第一步就在於文字的預處理和正規化 (Normalize)。文件正規化的流程開始於架構分割(Structure Segment),可以將一篇文章根據不同需求切割成段落或句子。接著會進行記號化(Tokenize),像是在處理中文字時,會將詞跟詞記號化,而不是一個字一個字讀。下一步則是將文字正規化 (Normalize)。在處理英文文檔時,通常會在Lemmatization和Stemming之間做選擇。這兩者之間最主要的差別在於,lemma會盡可能把恢復成字典上有的字,stemming則會把文字的後置 (suffix)整個切掉而不在意切掉後的字是不是字典上有的字。
那麼,我們來試試預處理一個文件吧。首先,我從我的一個網站中爬下一段HTML:
text = '''
<body>
<!-- JavaScript plugins (requires jQuery) -->
<script src="http://code.jquery.com/jquery.js"></script>
<!-- Include all compiled plugins (below), or include individual files as needed -->
<script src="js/bootstrap.min.js"></script>
<div class="container">
<div class="page-header">
<h3>About Me</h3>
</div>
<div class="page-info">
A web developer with experience in a variety of exciting projects, with the most up-to-date and relevant programming foundations available. My wide experience in
a diversity of technologies guides me with the best way to get your business success.
My interest in academic leads me to research in the field of NLP(Natural Language
Processing). Other than the knowledge in CS/IT, I'm also a broad learner who loves
to read each and every kind of books.
</div>
</div>
</body>
'''
我們可以透過正規表示法來移除HTML標籤:
import re
text = re.sub("<[^>]+>", "", text).strip()
print(text)

我們可以清楚地看到,在標題(About)和文字之間有一些跳行符號。在我們進行記號化(Tokenize)之前,讓我們先把這些跳行符號取代成空格吧。
text = text.split("\n\n")[1].replace("\n", " ")
print(text)

接著,我們可以把文件分割成句子。雖然用過Python的朋友都知道可以單純的用.split()來處理現在這個例子,但我們還是試著用NLTK提供的句子分割器,為了因應未來可能要處理之更難的文字。
import nltk
nltk.download('punkt')
sent_segmenter = nltk.data.load('tokenizers/punkt/english.pickle')
sentences = sent_segmenter.tokenize(text)
print(sentences)

除了分割器,NLTK也能幫助字詞記號化。我們將範例文件中的第一個句子分別用python split和NLTK透過正規表示法寫出來的記號器做個比較吧!
word_tokenizer = nltk.tokenize.regexp.WordPunctTokenizer()
tokenized_sentence = word_tokenizer.tokenize(sentences[0])
print(tokenized_sentence)
print(sentences[0].split(" "))

NLTK記號器能夠正確地將逗點和"up-to-date"這樣的自分割出來。當然,這樣的功能有時候是幫助我們的,在一些應用上這功能反而不是我們所希望發生的。
接著,我們來測試Lemmatization。NLTK也有lemmatizer,在使用時上通常會需要先知道句子的詞性標注。在這個範例中,我們簡化這流程,先將輸入的文字用動詞來lemmatize,若發現文字沒有發生變化,我們再用名詞的lemmatizer來試試看。
nltk.download('wordnet')
lemmatizer = nltk.stem.wordnet.WordNetLemmatizer()
def lemmatize(word):
lemma = lemmatizer.lemmatize(word,'v')
if lemma == word:
lemma = lemmatizer.lemmatize(word,'n')
return lemma
print([lemmatize(token) for token in tokenized_sentence])
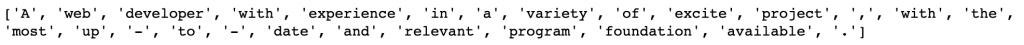
現在我們也來試試看Stemming,我們使用NLTK內建的Porter Stemmer:
stemmer = nltk.stem.porter.PorterStemmer()
print([stemmer.stem(token) for token in tokenized_sentence])

大家可以觀察看看,在進行lemmatization和stemming之前的文字和之後的文字分別有哪些變化!
今天的code也都在Jupyter Notebook裡面,大家可以到這裡下載。

